Federated Learning for Next-Word Prediction
Us young talents in Västerås were tasked by the Scaleout team to select an industry, use-case and develop a project using their platform for federated learning.
The industry we choose was mobile devices and the use-case was next-word prediction because of it's broad adoption.
To get started we divided the project into 4 main objectives:
- Foundation model that works well for the use-case
- User Interface for better human validation and visualization of result.
- Learn the Fedn platform by deploying their example project
- Moving our foundation model to the Fedn platform
Foundation Model
We started by trying many different model architectures, tokenization methods and training data. What we found the best result in while still having a small model that can run and train on a phone was:
- LSTM Recurrent Neural Network with a sequence length of 10.
- Tokenization via BERT token → token_id mappings and training our own embedding layer
- A 50/50 mix of highly cleaned twitter data from the Sentiment 140 dataset and Wikipedia data.
This model was trained on a variating sequence length with padding tokens that we made the LSTM ignore.
An example on how this looks is for the sequence “next word prediction": the model would get trained on
“next _ _ _ _ _ _ _ _ _ ”
“next word _ _ _ _ _ _ _ _ ”
“next word prediction _ _ _ _ _ _ _ ”
The size of the model was 12 million parameters whereof only 400 000 was in the LSTM model and the rest were a decoding layer for embeddings.
The training took ~30 minutes on a 4080 super GPU.
Human Validation
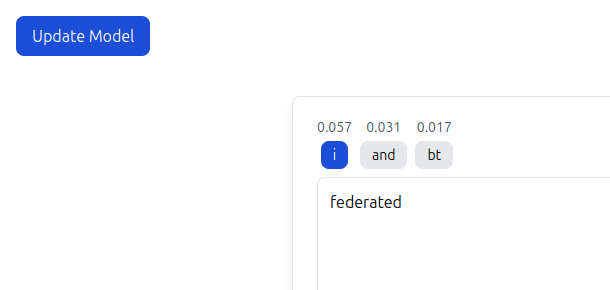
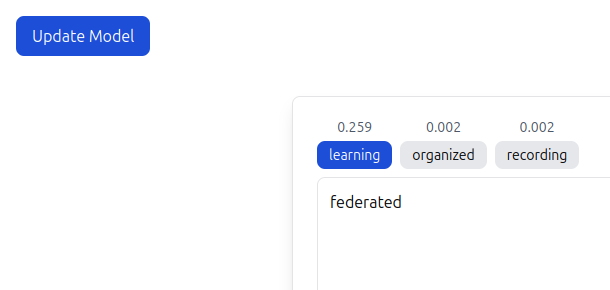
When we iterated on the foundation model we changed parts that would also change how the loss and accuracy was calculated. One example of this is changing tokenization method from per-word to BERT.
This would now change the loss as the output tokens are smaller and most likely easier for the model to predict or find a local minimum.
Therefore we developed a User Interface where we could we how the model behaves and from that determine if we liked it better or now.
Getting started with Fedn
Once the foundation model was good enough for our standards we began to dive into fedn and the “getting started" guide they had.
This was done quickly and now we knew how the platform worked and we were ready to move our project which to this point was in a singular notebook and a simple flask server with a svelte project
Moving our Project
When moving our project to the structure of a fedn one was where we found the most challenges.
The Multiple File Requirement
What we found to slow us down the most when moving to a fedn project was the structure. At the moment it is divided into different files for each event. For example for training there is a train.py file which take the arguments (model_in, model_out)
What we liked was how the “function” of a file was structured but something we really would like to see from Scaleout is to keep the events but have them in a single file and use the functions as plain python functions and not files.
Compute Packages
The compute packages is something else we found annoying. To get this project into a final product we iterated over 34 compute packages which uploading to Scaleout and downloading to test is a 5 minute process.
This is the same process as a production project would use and for those purposes it works great. It is only when developing a fedn project and having to wait 5 minutes to see how one line of code changed it that makes it annoying so the capability to test compute packages locally would be great!
Command Line Requirement
We found running compute packages off the command line to be weird as it doesn't really work in production where you would want a single binary with all the code and functionality.
The use of this command also prevented us from running our user-interface automatically with the client (we think because it required multi threading)
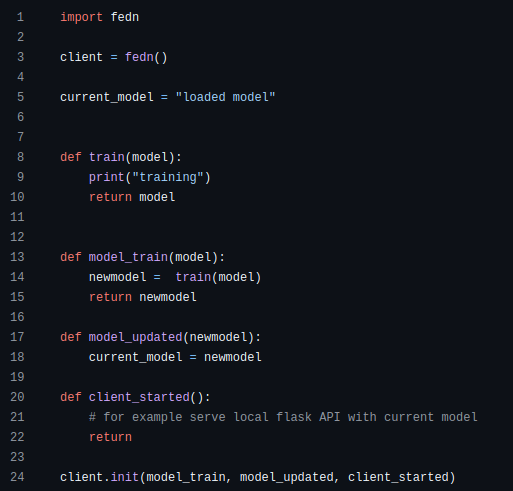
What we think would solve most of these problems and we later got to know is currently worked on is this code snippet. This would solve the issue with the multiple file requirement as everything would be ran off a central python file.
It would also solve the command line requirement problems if authentication could be done through this file somehow.
The final product is a foundation model, web-UI, and a fedn project that works with Scaleout.
When presenting this project we managed to train it on hard-coded data from Scaleout's documentation.
After the model had trained in a client and aggregated through Scaleout's platform, we could see a notable difference in how it could predict words related to federated learning.
This proved that it is possible for a next-word prediction model (like in your phone) to learn new words privately based on the messages you type.