


Röda Korset
The Swedish Red Cross in Umeå, aims to develop a real-time voice translation app to facilitate communication with migrants. The tool will feature "Push to talk" functionality to record conversations that can be translated between Swedish, Ukrainian, and potentially other languages. The app will also analyze conversation data to identify expressed needs and structural barriers, aiding in project evaluation and mapping.
The data for this project will be collected through the app, combining highly secure internal datasets. A part of the project will also look into how AI can be applied to identify and anonymize private data in the conversations. The project will include interviews with migrants and Red Cross staff to better understand their experiences and needs, ensuring the tool is effectively tailored to its users. Technical planning will explore existing AI platforms and APIs for voice recognition and translation. Data handling and privacy will be a priority, adhering to strict data protection laws.
Expected Outcomes
The translation tool is expected to significantly improve communication between Red Cross volunteers and the migrant communities they serve, enhancing the effectiveness of their integration efforts. Analyzing the data collected from the app will provide valuable insights into the needs and challenges faced by migrants, which can inform future projects and interventions. This project will also serve as a pilot for potential broader implementation across the Red Cross network.
|
2024-08-16 13:41
Image
As we wrap up the AI for Impact Talent Program, we're thrilled to share the final details of our app, which has been designed to enhance communication and provide valuable information to users in various contexts. Here's a closer look at the features we've developed and how they work:
Our app’s translation feature allows seamless communication across languages. Users can speak into the app, which transcribes the speech into text, translates it into the selected language, and plays it back as audio. The entire conversation is visually displayed on the screen in speech bubbles, making it easy to follow and review. A reset button clears the conversation screen, allowing users to start fresh whenever needed. Importantly, users can choose to consent to data collection for statistical purposes, helping us improve the service, while still maintaining full functionality without consent.
The Community Guide is an invaluable resource for users seeking information about local resources, integration tips, and recommendations for activities and attractions. Questions can be asked either by speaking or typing, and responses are provided both as text on the screen and as audio. The app offers the flexibility to toggle between two selected languages within the conversation, and users can choose to disable the audio if they prefer text-only responses.
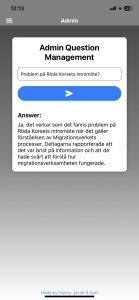
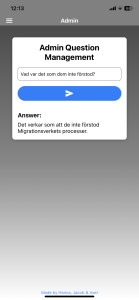
For administrators, the app includes powerful tools for analyzing user interaction data:
Our app leverages AI models through several API integrations:
User privacy is a top priority. The app’s translation feature allows users to consent to data storage for statistical analysis, but this is entirely optional. The app remains fully functional without data storage, and all other interactions within the app are processed in real-time without saving any data. This ensures that users, particularly those in vulnerable populations, can use the app without pressure to consent to data collection. |
|
2024-08-16 13:13
Image



This is the final week of the AI for Impact Talent Program! This week, we've focused on polishing the app by fixing a few minor bugs, commenting on the code, and cleaning up everything. We also sent an .apk file to the Swedish Red Cross in Umeå so they can install it on their Android devices. It’s incredibly exciting to see the app being used in the Red Cross’s operations, and we’re eagerly awaiting their feedback! We also dedicated a lot of time to preparing our presentation and recording a demo. On Thursday, we had our final presentations, which was an incredibly rewarding experience! It was fascinating to hear about the other teams' projects—everyone did an outstanding job! After the presentations, we celebrated with some cake and then enjoyed a group dinner, which was the perfect way to conclude a fantastic summer. In addition, we were filmed for a video that AI Sweden is producing about the program, which was a lot of fun! Looking ahead, we have a few additional days set aside for a proper handover of the project to the Swedish Red Cross. We’ll be documenting how our code works to ensure a smooth transition for them to take over the app’s maintenance. We’ll also be giving a presentation to staff at various Red Cross offices to help spread the word about our app within the organization. To wrap up this final post, we want to extend our thanks to AI Sweden for this incredible opportunity, to the Swedish Red Cross for their collaboration, and to all the other teams in the talent program for their inspiration! We are extremely grateful for this experience and have learned so much during the program. |
|
2024-08-16 12:30
Image
Hi, This week, we successfully completed the development of all the new features for the app. We focused on three major updates: 1. Complete Redesign: We implemented a brand-new design across the app, selecting a consistent color theme that is now applied to all screens. 2. Multilingual Translator Tool: We've enhanced the translator tool to support multiple languages. Users can now select two languages at the beginning of a new conversation. The app automatically detects which of the two languages the person is speaking and translates the text into the other language. This eliminates the need to specify the language before each talk in a conversation. The available languages are Swedish, Ukrainian, Russian, Spanish, German, French, and English. 3. Keyword Analysis Chart: In the Admin Assistant screen, we added a chart that displays the most common themes discussed in conversations. When a conversation is reset, the entire conversation is stored as a string. We then use the OpenAI Embeddings API to vectorize both the conversation and a set of predetermined keywords. By performing a cosine similarity search, we can identify which keywords were discussed in each conversation. The chart shows the number of conversations associated with each keyword, which can be filtered by month, week, day, or for all available data. We have also introduced a pop-up that appears at the start of each new conversation in the translator tool. The pop-up explains that data is stored for statistical purposes and gives users the option to consent or not consent. If a user does not consent, they can still use the app, but their conversation will not be stored. Consequently, admins will not be able to ask questions about that specific conversation in the chatbot, and the keywords discussed will not be updated. With these updates, we have completed all the planned functionalities for the app. We're looking forward to the final week of the program to wrap everything up! |
|
2024-08-05 10:20
Post
We are back in office after two weeks of vacation. We have now completed five weeks, and have three weeks remaining. When we left for vacation two weeks ago, we had accomplished the following:
Coming into week 6, with the Translation feature and Community Guide feature completed, we wanted to focus on the last remaining task - the RAG functionality for storing and analyzing the conversations. The goal of this feature is for the admin of the app (for instance the local manager of a Red Cross branch) to be able to keep statistics and analyze the conversational data in order to identify expressed needs and structural barriers, aiding in project evaluation and mapping to improve the operations. This will be done using the RAG (Retrieval-Augmented Generation) technique. In summary, RAG works by storing conversations as vectors, querying a vector database to retrieve relevant conversations, generating a response using a language model, and delivering the response to the user as an answer to the question, based on the context from the stored data. How GDPR, acceptance of terms, and how AI can be applied to identify and anonymize private data in the conversations, is something we will come back to and put focus on later. At first, we wanted to implement one type of RAG called GraphRAG. GraphRAG is a technique that enhances the retrieval process by leveraging the structure of a graph to improve the relevance and accuracy of the retrieved information. It does this by considering the relationships between different nodes (documents or passages) in the graph and using this information to better match the query with the most relevant documents. This is a technique that we think matches our specific use case best, since we want to gather data from a specific topic over a wide range of vectors. However, the GraphRAG technique comes from very recent research, hence there is very little information and guides on how to implement it. It also requires Python language, and our tech stack is running on Node.js and JavaScript. During the week, we worked on different approaches on ways to implement the RAG functionality. These approaches included: trying out to use a Function App to run the Python script by calling a separate API, implementing GraphRAG in python, using the LangChain framework to build RAG in both Python and JavaScript, and with the help of different vector databases as ChromaDB, Cosmos and MongoDB. At the end of the week, we managed to successfully implement a fully functional Baseline RAG (i.e. “normal” RAG) by ourselves, without the help of any RAG-framework like LangChain. We felt that this approach was the best for us to learn the most, fully understand the RAG functionality as well as to easily control and manage the RAG pipeline in our code. How does our RAG pipeline work?
|
|
2024-08-05 07:46
Post
Hi, This week, we focused on finalizing the deployment from last week and preparing the app for organizational testing. One issue we encountered was that our devices were having trouble retrieving and playing processed audio files from Azure blob storage. We resolved this by enhancing the file retrieval function on the client side. With the deployment now successful, our attention shifted to enabling multiple users to access the app simultaneously, a key reason for hosting the server in the cloud. To achieve this, we needed to ensure that the correct audio files are matched with the appropriate users in the database—preventing the mix-up of translations between users. Below is an overview of the solutions we considered and the approach we implemented:
Next, we concentrated on optimizing the app for both Android and iOS devices. Our client’s primary requirement is that the app be functional on Android, but since our team primarily uses iPhones, we also wanted to ensure compatibility with iOS. However, the process of building apps for these two platforms differs significantly, especially when trying to avoid costs. For Android, we used the following approach:
For iOS, however, the process is more complicated due to Apple's restrictions on free app distribution:
After thorough consideration, we decided not to proceed with building the app for iOS at this time. The lack of a cost-effective solution that didn’t require manual client operation made it impractical to support iOS alongside Android. As a result, we are focusing our efforts exclusively on optimizing the app for Android devices. We also transitioned from using OpenAI's APIs for GPT-3.5-turbo, Whisper, and Text-to-Speech (TTS), along with the OpenAI API key, to utilizing these APIs through Azure, using an Azure API key provided by the Swedish Red Cross. On the design front, we've implemented a homepage that appears as soon as the app is launched. From the homepage, users can navigate to either the translation page or the community guidance page. Lastly, we have developed a login page to restrict access to authorized Red Cross users only, ensuring that the app is used solely for its intended purpose of communicating with Ukrainian refugees. However, we still need someone from the Red Cross operations team to configure a redirect URI before we can finalize this feature. To wrap things up, our team will be taking a two-week vacation, but we're excited to continue developing the app when we return. After the break, our focus will be on creating an admin page that includes a chatbot using Retrieval-Augmented Generation (RAG). This feature will allow admin users to ask for statistics on the conversations, making it easier to track and analyze interactions within the app. |
|
2024-07-05 12:58
Post
Deployment time! This week, our focus was to implement our app into the IT infrastructure at the Red Cross, to enable deployment and demo testing in the real world! We also made our app working smoothly on Android devices. We kicked off the week by enabling Android compatibility. Previously, our App was only tested on iPhones, which caused some problems on Android devices. The main challenge was how we processed audio files and used the embedded audio player within the devices. While iOS uses AVPlayer, Android uses ExoPlayer. The solution was to come up with a new algorithm to ensure one audio file finishes playing before starting the next. So now it works seamlessly on both iPhones and Androids - great stuff! With Android issues sorted in the beginning of the week, we spent the rest of the week focusing on deploying our app on Microsoft Azure, wanting to shift our backend from running locally to running in the Azure environment instead. This is a necessity to enable the Red Cross to demo test our mobile application within their actual organization. However, this deployment has been trickier than expected - here’s a snapshot:
Some tech-nerdy explanations: The major problem during the deployment to Azure has been the re-building and re-coding of our server functionality to handle the uploads, access and downloads of the audio files. Previously, everything was managed in the local computer's file system, but when moving the server and storage to Azure, a lot of the functions needed to be revised. A specific problem is the handling of audio files directly in memory, since the Whisper API needs a proper file to proceed and transcribe the audio. Here we managed to use Buffers (temporary holding spot for data being moved from one place to another). This also lets us skip the process of uploading the file to the Blob Storage before downloading it again and put it through the API. However, Buffers are not seen as files, which the Whisper API expects. To overcome this, we are using Form-Data that are file-like objects which can contain the binary information directly in memory without the need of an actual storage place locally. The Buffer is first converted to .wav format, and then appended to the Form-Data object. With the help of Axios (instead of using OpenAI's official Node.js library) we are then able to send this audio “file” into Whisper API and get the transcription back. Then this transcription is processed through the rest of the API:s, and finally after TTS (Text-to-Speech) is done, the translated audio Buffer is uploaded to Azure Blob Storage in the wait to be played, and then directly deleted after being played. Azure Blob Storage also has a SDK for Node.js which helped the development process. Hence, moving into next week, our primary goal is to get our app fully functional in the Azure environment. Once this is achieved, we can fully focus on adding new cool features and getting the app running in the Red Cross organization as soon as possible! Until next week! /Team |
|
2024-07-02 12:51
Image




Good evening! The third week of the AI for Impact Summer Talent Program is done, and it has brought a lot of valuable insights and learnings. This friday, we had a check-in meeting with the other teams in the program where everyone presented their work so far. It was loads of fun and we are very impressed with everyone's work so far! The knowledge sharing between the teams is really helpful and rewarding. We have made a lot of progress this week with our mobile app for the Red Cross. Starting the week, we focused on fine-tuning our translation model. We realized that the OpenAI Whisper (Speech-to-Text) model had a hard time transcribing the audio files without the relevant context of the talk when using our new script that automatically cuts the audio as soon as there is a natural pause while talking. We solved this issue by prompting Whisper with the previous transcriptions of the talk, to make the model understand the context and therefore easily predict what to transcribe from the next audio files. We also made some code updates to improve the speed of the model and to correct some button-bugs. We have successfully added chat-bubbles to show the text on the screen. When the user talks, the text pops up in a chat-bubble as it gets transcribed, to ensure that it is correct. As the user continues to talk, the chat-bubble gets filled with more text. When the user is done and wants it translated, the stop-button gets pressed, and the chat-bubble turns into the translated language simultaneously as the translated audio is played. This way, the second user is able to read the translated text too when hearing the translated audio. Moving on, it works the same for the second user when speaking back in the other language. Our app is displaying the conversation with chat-bubbles on both sides, like a normal conversation-app, ensuring that all the Swedish speaker says is displayed on the right side in blue color, and what the Ukrainian speaker says is displayed on the left side in white color. An additional feature is that all chat-bubbles are clickable, so when clicking on one, it instantly changes the text to the opposite language, so that each user can read the whole conversation in its own language. Our second major feature we have completed this week is the Community Guide. Via a menu button in the top left corner, users can switch to a new page where they can access the Community Guide. In the Community Guide refugees can ask questions regarding Swedish society, either by recording their question or by typing it in the search bar. The question is answered by OpenAI's GPT-4 API, and the response is both displayed on the screen in text and played as audio in the same language the question was asked. The GPT-4 model is prompted with a task description and guidelines on how to behave like a community guide for Ukrainian migrants. We have also implemented a toggle function similar to the one in the translation feature. When clicking on either a question or an answer, the text is translated to Swedish/Ukrainian. This is beneficial if a Ukrainian refugee wants to ask or double check a Swedish Red Cross volunteer about something that the Community Guide has answered. Finally, our last progress of this week has been to get the deployment pipeline process started. We have had meetings with the Swedish Red Cross IT Department and gotten access to their IT infrastructure, including Microsoft Azure. This will enable us to deploy and try demo versions of the mobile app directly via their IT infrastructure, facilitating the future implementation and hand-over of our product after the summer. We will dig deeper into this deployment pipeline next week. |
|
2024-06-24 08:58
Image
Hi, This week, we started by creating a private OpenAI account and purchased credits to test the APIs. Implementing OpenAI’s Whisper (Speech-to-Text), GPT-3.5-turbo, and TTS (Text-to-Speech) went smoothly using an OpenAI Node.js library and environment variables for API keys. We prompted GPT-3.5-turbo to translate the text to Swedish/Ukrainian based on the detected source language. After completing the implementation of all three APIs, we began testing the button functionalities. We programmed the "Prata" button and “Avsluta” button to stop playback if pressed during playback and allow the user to speak again or end the session, respectively. The major challenge during this week has been the translation process. At first we recorded the whole talk (multiple sentences) from each person before we put that audio file into the recording process. Initially, there was a significant delay between pressing the "Sluta prata" button and playing the translated audio. This delay was at least 5 seconds, before the translation process was done and read out loud. This delay occurred because we had to wait for Whisper to transcribe the audio file, GPT-3.5-turbo to translate it, and TTS to convert the text back into audio. We explored various methods for real-time playback and streaming but found that only TTS supported real-time playback, which wasn't enough to solve the overall delay issue. Therefore we enhanced the model by making an automated script that cuts the audio as soon as there is a natural pause (in between sentences), and then that audio file is put through the translation process while the next audio file is being recorded during the rest of the talk. This pioneered the model with a waiting time of less than 1 second before hearing the translated audio, since everything is now happening simultaneously. This way, the initial recordings can be played immediately after pressing the "Sluta prata" button, while the remaining snippets are processed concurrently during playback. Next week, we will further explore the implementation of small audio snippets. We discovered that Whisper sometimes struggles to transcribe small snippets without the context of the surrounding sentences. Following that, we will implement real-time text display on the app screen synchronized with the audio playback, to enable reading. |


















